前言
链表是线性表的一种高级结构,栈为先进后出,队列为先进先出
单链表与队列
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素(这组存储单元科室是连续的,也可以是不连续的)。因此,为了表示每个数据元素ai与其直接后继续数据元素ai+1之间的逻辑关系,对数据元素ai来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息。这两部分信息组成数据元素ai的存储映像,称为结点(node)。单链表的存储结构为
//单链表
typedef struct LNode {
Elementype data;
struct LNode *next;
}LNode,*LinkList;
在单链表的第一个结点之前附设一个结点,称之为头结点。头结点的数据域可以不存储任何信息,也可以存储如线性表的长度等类的附加信息,头结点的指针域存储域存储指向第一个结点的针(即第一个元素结点的存储位置)
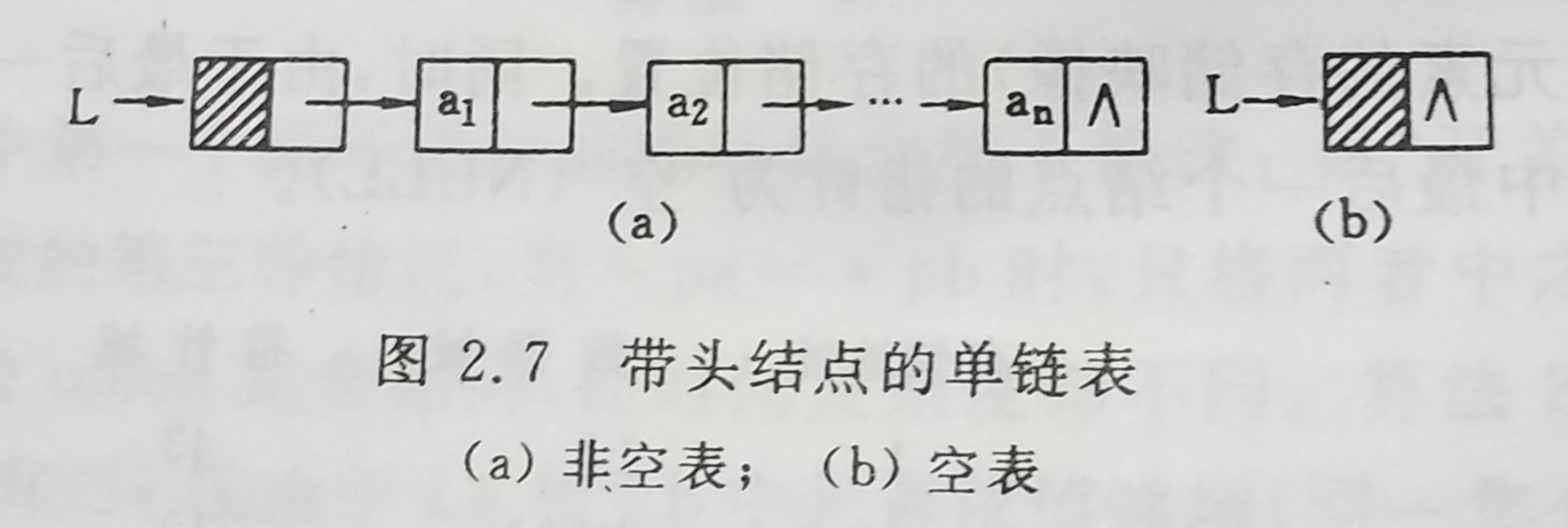
同时初始化链表
void initList(LinkList &L) {
L = (LinkList)malloc(sizeof(LNode));
L->next = NULL;
}
为所赋值的链表分配空间并且将下一个指针域指向空位置。
插入链表
新建一个链表指针p,在每一个新的结点上分配空间,赋值数据给改链表的数据地点,将该链表p的next值接在L的next指针域中也就是NULL值,然后将现在的L的next指针接在p的头结点中,如代码所示
void CreateNode(LinkList &L,int n) {
LinkList p;
//插入链表
for (int i = n; i > 0; --i) {
p = (LinkList)malloc(sizeof(LNode));
scanf("%d", &p->data);
p->next = L->next; //输入元素值
L->next = p; //插入到表头
}
}
Status ListInsert_L(LinkList &L, int i, Elementype e) {
// 在带头的节点的单链线性表L中第i个位置之前插入元素e
LinkList p,s;
p = L;
int j = 0;
while (p && j < i - 1) { p = p->next; ++j; } //寻找第i-1个节点
if (!p || j > i - 1) return ERROR; // i 小于1或者大于表长加i
s = (LinkList)malloc(sizeof(LNode)); // 生成新节点
s->data = e; // 插入L中
s->next = p->next;
p->next = s;
return OK;
}// ListInsert_L
插入链表
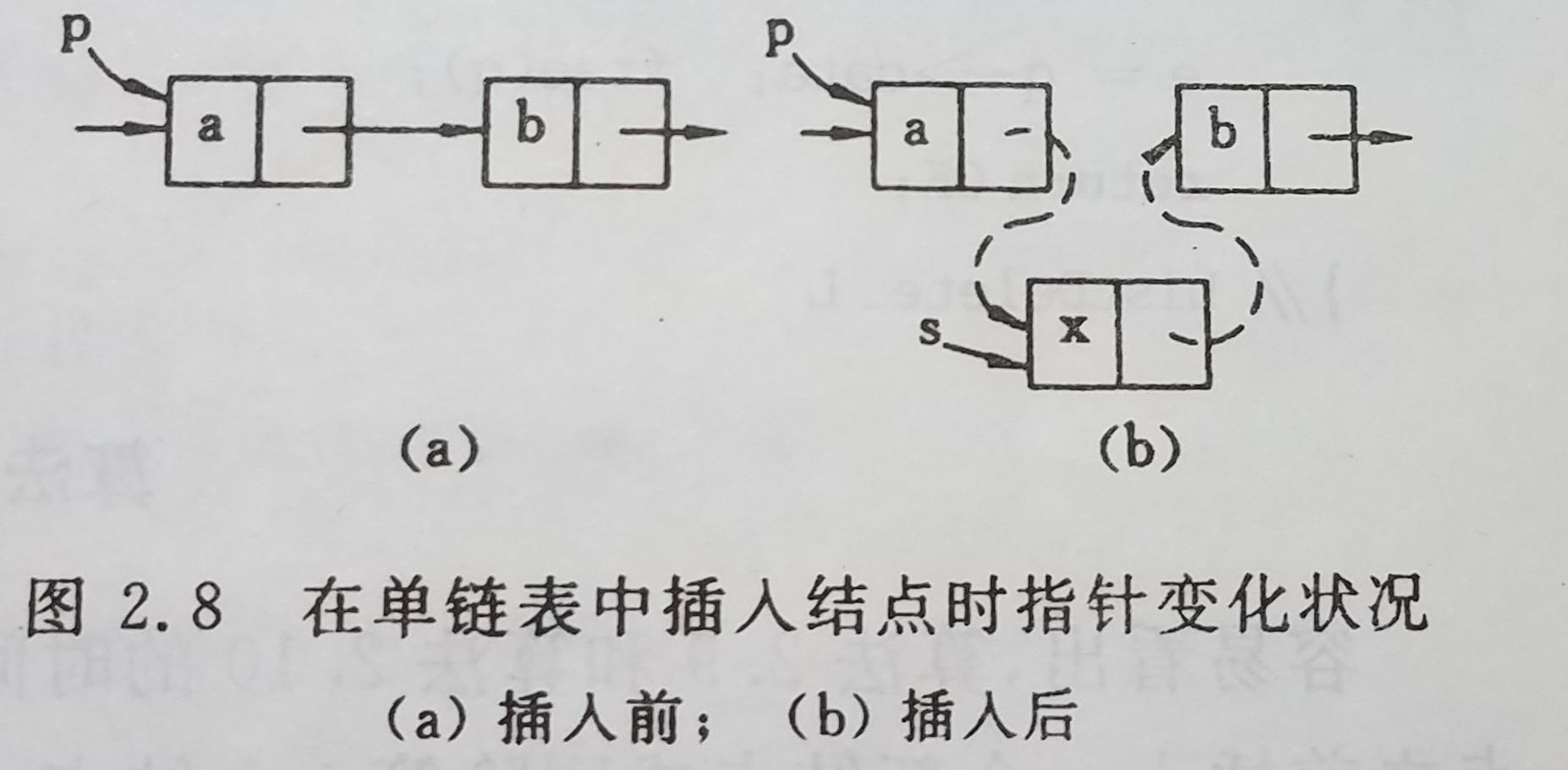
为插入一个链表x,首先生成一个数据与为x的结点,然后插入在单链表之中。同时修改结点a中的指针域,令其指向结点x,而结点x中的指针域应该指向结点b,从而实现3个元素a、b和x之间逻辑关系的变化。插入后的单链表如图所示。假设s为指向结点x的指针,则上述指针修改用于据描述即为
s->next = p->next;p->next = s;
删除链表
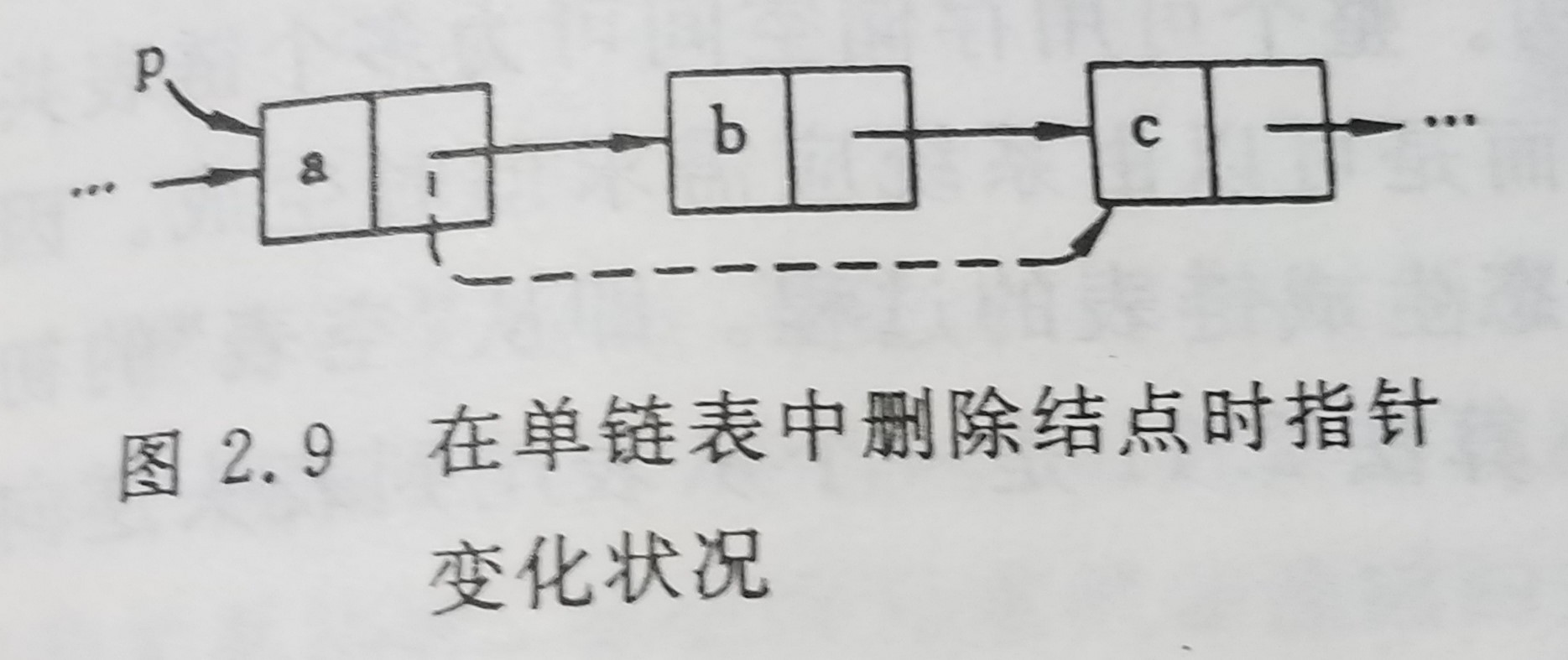
在删除元素b时,为在单链表中实现元素a、b和c之间逻辑关系的变化,仅需修改结点a中的指针域即可。假设p为指向结点a的指针,则修改指针的语句为
p->next = p->next->next;
Status ListDelete_L(LinkList &L, int i, Elementype &e) {
// 在带头结点的单链线性表L中,删除第i个元素,并由e返回其值
LinkList p = L,q;
int j = 0;
while (p->next && j < i - 1) { // 寻找第i个结点,并令指向其前趋
p = p->next;
++j;
}
if (!(p->next) || j > i - 1) return ERROR; // 删除位置不合理
q = p->next; // 删除并释放结点
p->next = q->next;
e = q->data;
free(q);
return OK;
}
合并链表
设立三个指针pa、pb和pc,其中pa和pb分别指向La表和Lb表中当前待比较插入的结点,而pc指向Lc表中当前最后一个结点,若pa->data <= pb->data,则将pa所指结点链接到pc所指结点之后,否则将pb所值结点链接到pc所指结点之后。当LA和LB为非空表时,pa和pb分别指向La和Lb表中第一个结点,否则为空;pc指向空表Lc中的头结点,当其中一个为空时,说明有一个表的元素已归并完,则只要将另一个表的剩余段链接在pc所指结点之后即可。由此得到归并两个单链表的算法
//合并链表
void MergeList_L(LinkList &La, LinkList &Lb, LinkList &Lc) {
// 已知单链线性表La和Lb的元素按值非递减排列
// 归并La和Lb得到新的单链线性表Lc,Lc的元素也按值非递减排列
LinkList pa,pb,pc;
pa = La->next;
pb = Lb->next;
Lc = pc = La; // 用La的头结点作为Lc的头结点
while (pa && pb) {
if (pa->data <= pb->data) {
pc->next = pa;
pc = pa;
pa = pa->next;
}
else {
pc->next = pb;
pc = pb;
pb = pb->next;
}
}
pc->next = pa ? pa : pb; // 插入剩余段
free(Lb); // 释放Lb的头结点
}// MergeaList_L
链表倒置
设置一个临时表指向L的next域,同时设置一个临时表q,将L的next指针切断并指向空域,然后当p不为空的时候将p赋值给q,p指向下一个next域,将L的next指针域指向q域,并切断q的next域,在将p赋值给q,将L后的整个next域全部赋值给q,然后将L的next域指向
q,一次循环,如图所示,代码如下
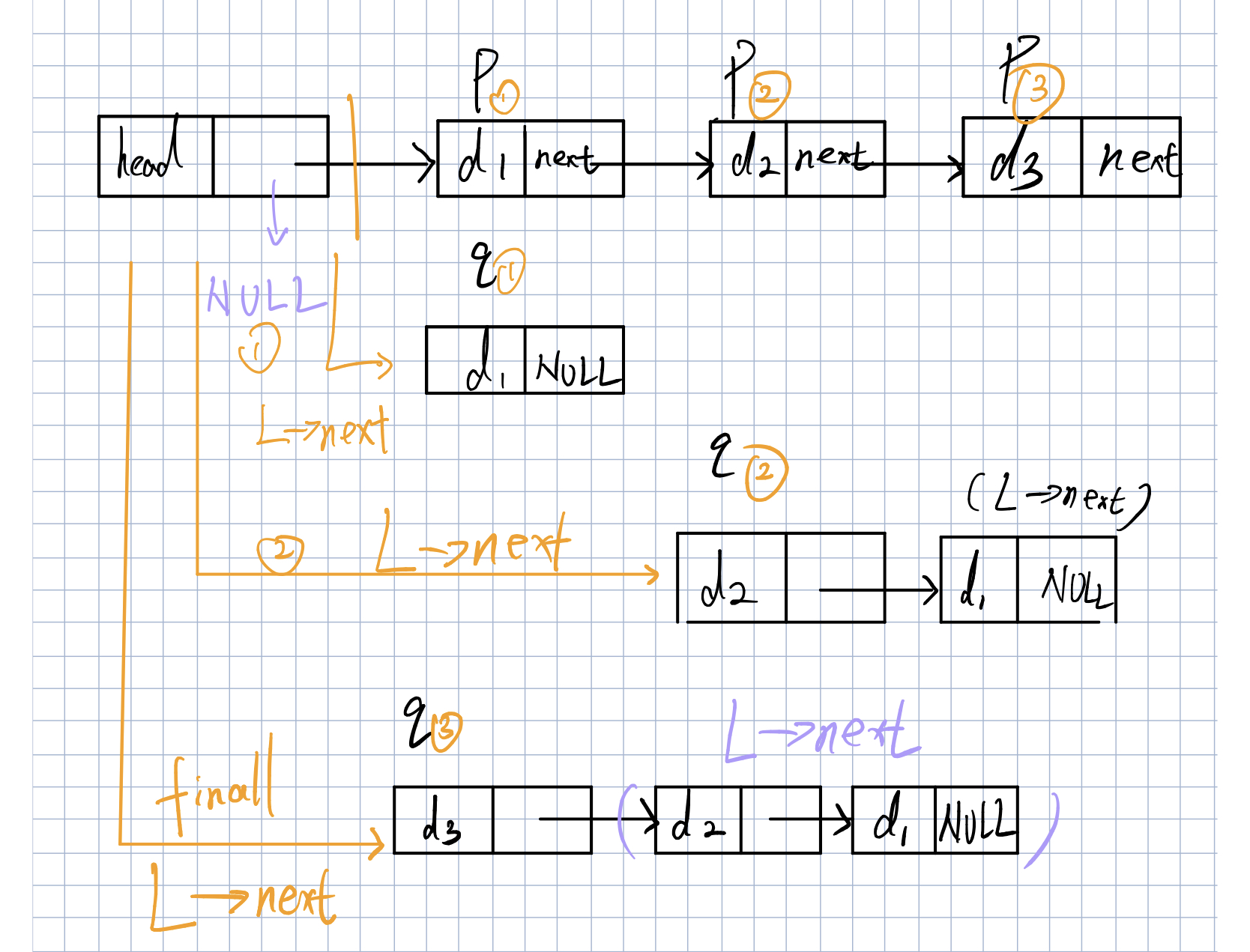
void reverse(LinkList &L) //L为带头结点的单链表
{
LinkList p = L->next, q;
L->next = NULL;
while (p)
{
q = p;
p = p->next;
q->next = L->next; // L所接上的所有之前q的链表全部接在q的尾部
L->next = q;
}
}
循环链表
循环链表时另以重形式的链表存储结构。它的特点时表中最后哟个结点的指针域指向头结点,整个链表形成一个环。由此,从表总任意结点出发均可找到表中其他结点,如图所示为循环链表,还可以多重链的循环链表
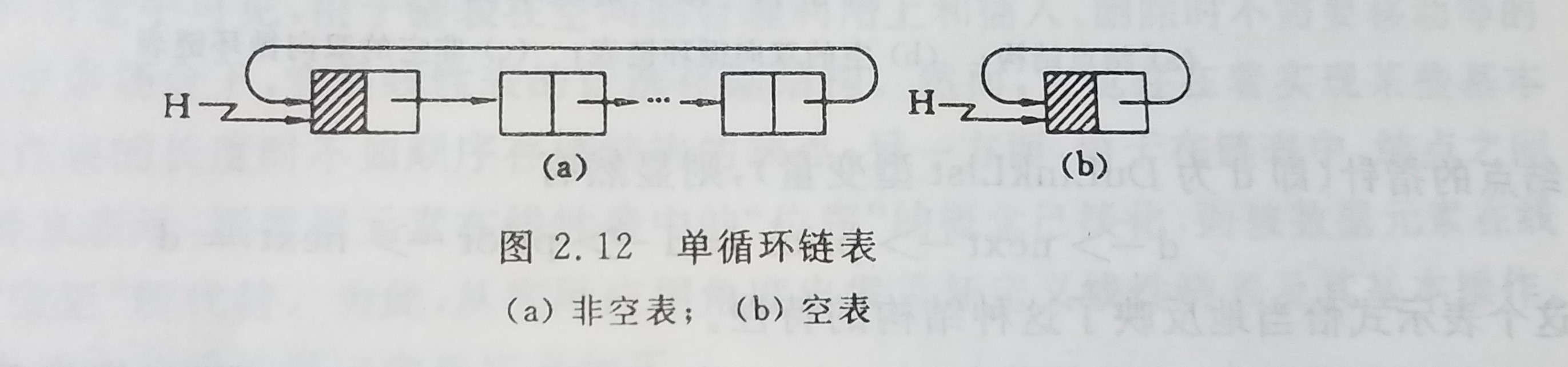
双向链表
在单链表中,NextElem的执行时间为O(1),而PriorElem的执行时间为O(n)。为克服单链表这种单向性的缺点,可以利用双向链表。其结构为
typedef struct DuLNode {
Elementype data;
struct DuLNode *prior;
struct DuLNode *next;
}DuLNode,*DuLinKList;
DuLinKList GetElemp_DuL(DuLinKList &L, Elementype e) {
DuLinKList p;
p = L->next;
while (p && p->data!=e) {
p = p->next;
}
return p;
}
Status ListInsert_DuL(DuLinKList &L, int i, Elementype e) {
//在带头结点的双链循环线性表L中第i个位置之前插入元素e
// i的合法值为1<=i<=表长
DuLinKList s,p;
if (!(p = GetElemp_DuL(L, i))) //在L中确定插入位置
return ERROR; // p=NULL,即插入位置不合法
if (!(s = (DuLinKList)malloc(sizeof(DuLNode)))) return ERROR;
s->data = e;
s->prior = p->prior;
p->prior->next = s;
s->next = p;
p->prior = s;
return OK;
}
双链表删除
Status ListDelete_DuL(DuLinKList &L, int i, Elementype &e) {
// 删除带头结点的双链循环线性表L的第i的元素,i的合法值为1<=i<=表长
DuLinKList p;
if (!(p = GetElemp_DuL(L, i))) //在L中确定第i个元素的位置指针p
return ERROR; // p=NULL,即位置不存在
e = p->data;
p->prior->next = p->next;
p->next->prior = p->prior;
free(p);
return OK;
}
栈和队列
栈是限定仅在表尾进行插入或删除操作的线性表。因此,对栈来说,表端有有特殊含义,称为栈顶,相应地,表头端称为栈底,。不含元素的空表称为空栈。栈又称为先进后出的线性表(简称LIFO),它的特点可用如下图表示
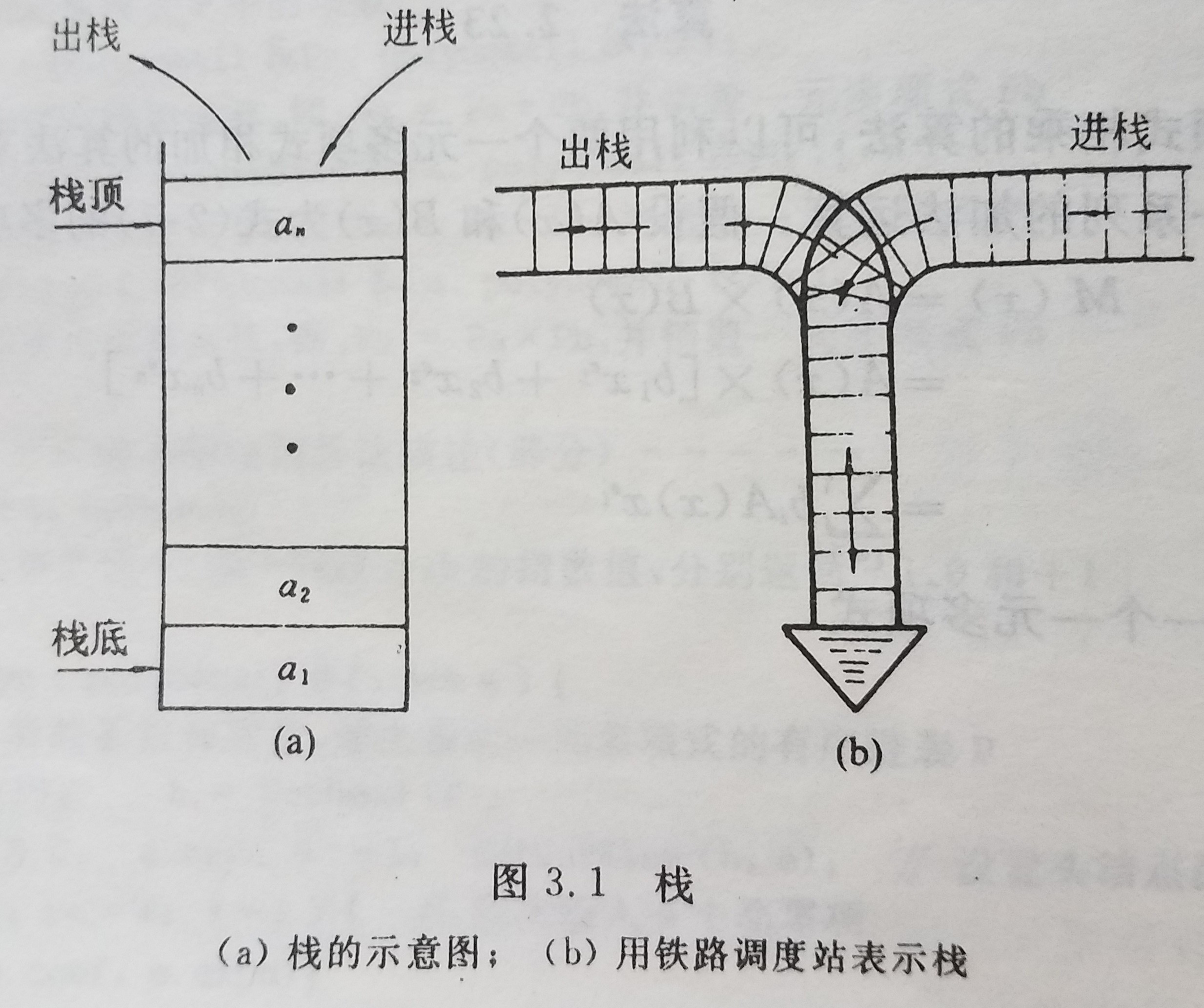
栈的基本结构
#define STACK_INIT_SIZE 100 //存储空间初始分配量
#define STACKINCREMENT 10; //存储空间分配量
typedef int SElemType;
typedef int Status;
typedef struct {
SElemType *base; //在栈构造之前和销毁之后,base的值为NULL
SElemType *top; //栈顶指针
int stacksize;
}SqStack;
初始栈
Status InitStack(SqStack &S) {
//构造一个空栈
S.base = (SElemType *)malloc(STACK_INIT_SIZE * sizeof(SElemType));
if (S.base) exit(-1); //存储分配失败
S.top = S.base;
S.stacksize = STACK_INIT_SIZE;
return OK;
}
入栈和出栈
Status Push(SqStack &S, SElemType e) {
// 插入栈元素e为新的栈顶元素
if (S.top - S.base >= S.stacksize) { //栈满,追加存储空间
S.base = (SElemType *)realloc(S.base, (S.stacksize + STACKINCREMENT) * sizeof(SElemType));
if (!S.base) exit(-1); //存储分配失败
S.top = S.base + S.stacksize;
S.stacksize += STACKINCREMENT;
}
*S.top++ = e;
return OK;
}
Status Pop(SqStack &S, SElemType &e) {
//若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR
if (S.top == S.base) return ERROR;
e = *--S.top;
return OK;
}
排序方法
根据压栈的循序寻找起出栈的顺序可以在插入当前值的时候即时取出,也可以在压入两个值之后再去除,可以使用栈的元素总数n!,然后除去重复的位置,图下列出两个小例子
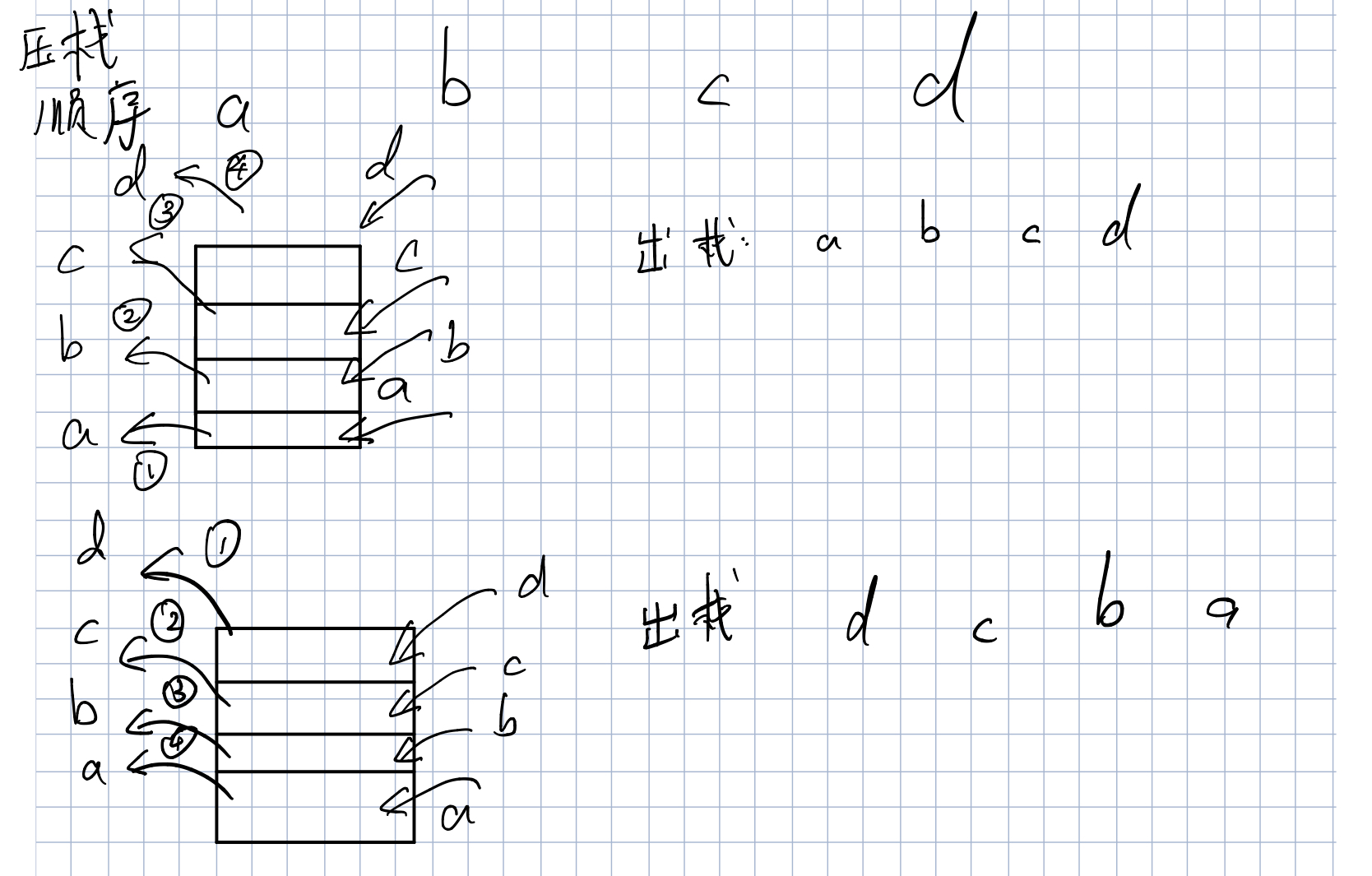
队列
和栈相反,队列是一中先进后出(FIFO)的线性表,它只允许的一段进行插入,而再另一端删除元素 。在队列中,允许插入的一段叫做队尾,允许删除的一端称为队头。 除了栈和队列,还有一种限定性数据结构是双端链表。
双端链表是限定插入和删除操作在表的两端进行的线性表。这两端非别称做端点1和端点2.也可像栈一样,可以用一个铁道转轨网络来必须双端队列,如图所示
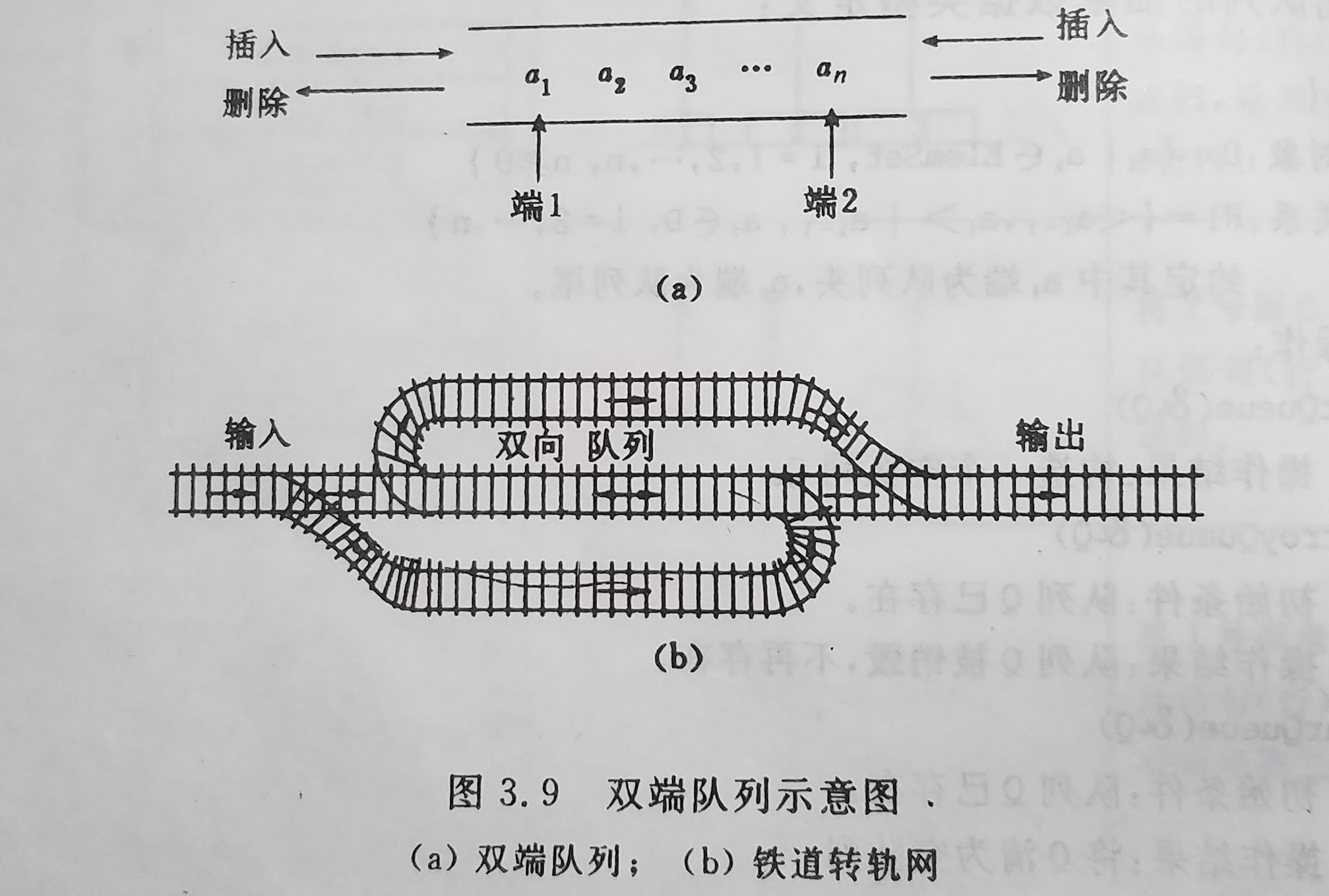
尽管在属安端队列看起来似乎比栈和队列更加灵活,但实际上在应用程序中远不及栈和队列有用。
链队列
即用链表的队列,起结构体为
typedef int QElemType;
typedef struct QNode {
QElemType data;
struct QNode *next;
}QNode, *QueuePtr;
typedef struct {
QueuePtr front; //队头指针
QueuePtr rear; //队尾指针
}LinkQueue;
入队和出队
Status EnQueue(LinkQueue &Q, QElemType &e) {
//插入元素e为Q的新的队尾元素
QueuePtr p;
p = (QueuePtr)malloc(sizeof(QNode));
if (!p) exit(-1);
p->data = e;
p->next = NULL;
Q.rear->next = p->next;
if (Q.rear == p) Q.rear = Q.front;
free(p);
return OK;
}
Status DeQueue(LinkQueue &Q, QElemType &e) {
// 若队列不空,则删除Q的队头元素, 用e返回其值,并返回OK
// 否则返回ERROR
QueuePtr p;
if (Q.front == Q.rear) return ERROR;
p = Q.front->next;
e = p->data;
Q.front->next = p->next;
if (Q.rear == p)Q.rear = Q.front;
free(p);
return OK;
}
循环队列
在队列的顺序储存结构中,除了用一组地址连续的存储单元依此存放从队头到队列尾的元素之外,尚需附设两个指针front和rear分别指示队列头元素及队列尾元素的位置,在C语言中,令front = rear = 0,每当插入新的队列元素是,队尾指针增加1;每当删除队列头元素
时,头指针增加1,因此,在非空队列中,头指针始终指向队列头元素,而尾指针始终指向队列尾元素的下一个位置。如图3.12所示
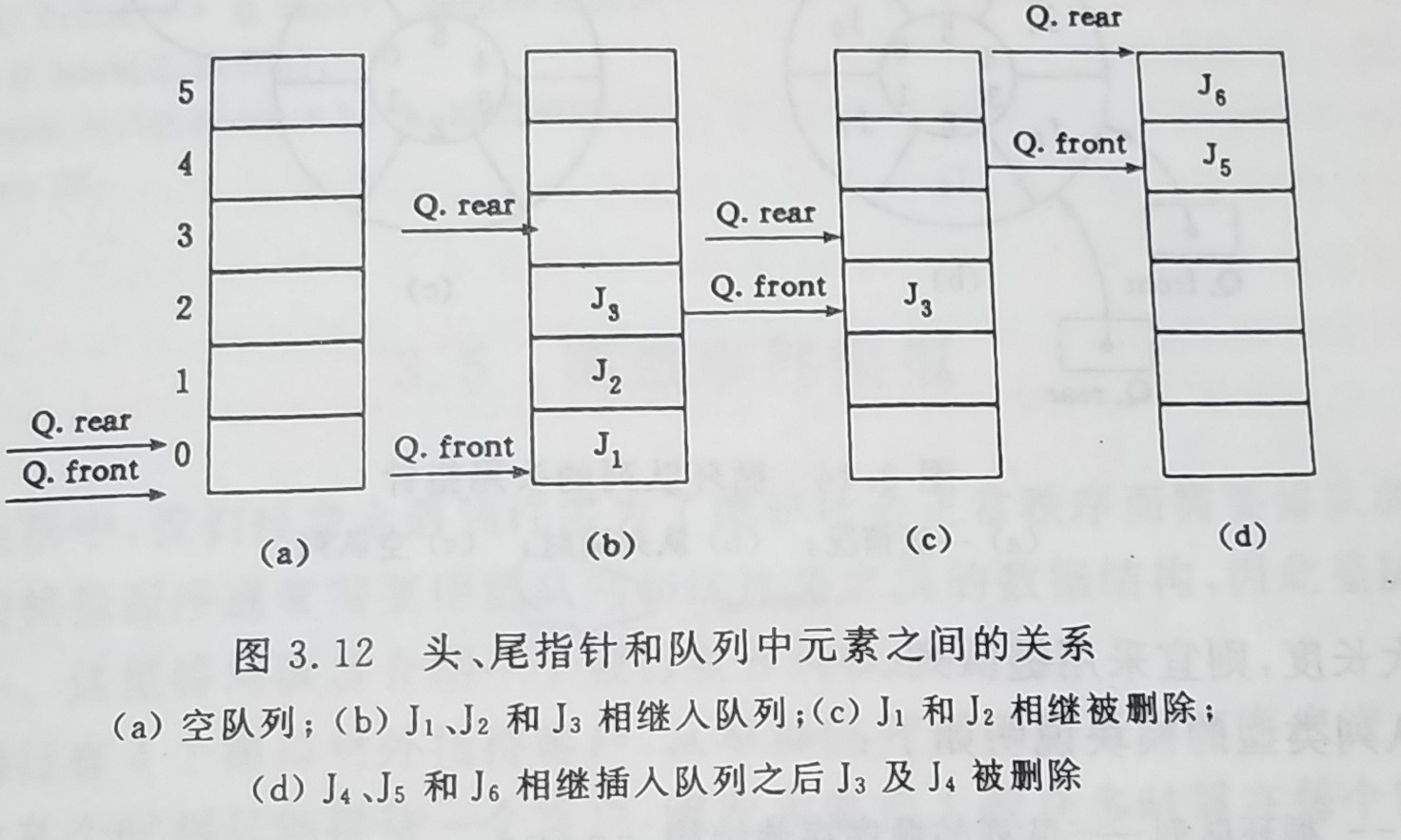
假设当前尾队列分配的最大空间为6,则当队列处于图3.12(d)时的状态不可再继续插入新的队尾元素。这时候循环队列的出现将顺序队列制造成一个环状的空间,则新的结构体为
#define MAXQSIZE 100 //最大队列长度
typedef struct {
QElemType *base; //初始化的动态分配存储空间
int front; // 头指针,若队列不空,指向队列头元素
int rear; //尾指针,若队列不空,指向队列尾元素的下一个位置
}SqQueue;
循环队列的计算、插入和删除
int QueueLength(SqQueue Q) {
//返回Q的元素个数,即队列的长度
return (Q.rear - Q.front + MAXQSIZE) % MAXQSIZE;
}
Status EnQueue(SqQueue &Q, QElemType e) {
// 插入元素e为Q的新的队尾元素
if ((Q.rear + 1) % MAXQSIZE == Q.front) return ERROR; //队列满
Q.base[Q.rear] = e;
Q.rear = (Q.rear + 1) % MAXQSIZE;
return OK;
}
Status DeQueue(SqQueue &Q, QElemType &e) {
// 若队列不空,则删除Q的队头元素,用e返回其值,并返回OK
//否则返回ERROR
if (Q.front == Q.rear) return ERROR;
e = Q.base[Q.front];
Q.front = (Q.front + 1) % MAXQSIZE;
return OK;
}
注意计算队列的长度一定要记得除以队列的最大长度
借此记下来以便以后查阅~