0X00前言
在编写vesta期间对比发现trivy的镜像扫描速度非常快,因此本文主要为clair,trivy与vesta对layer整合和整合后文件扫描分析。关于Docker Layer的原理本文不再赘述,其流程都可以简化为
解压镜像tar文件 -> 解析manifest.json文件 -> 依次对每一个layer进行处理
0X01 Clair
Clair作为一个老牌镜像扫描器,其出现也开辟了容器镜像扫描的道路。clair的核心引擎在claircore中,其在2022年7月9号采用了新的fetch Layer的方式,并且在2022年7月23号后删除了老旧的命令,具体可以参考commit,首先看看在这之前clair是如何解压分析layer的,大致流程如下
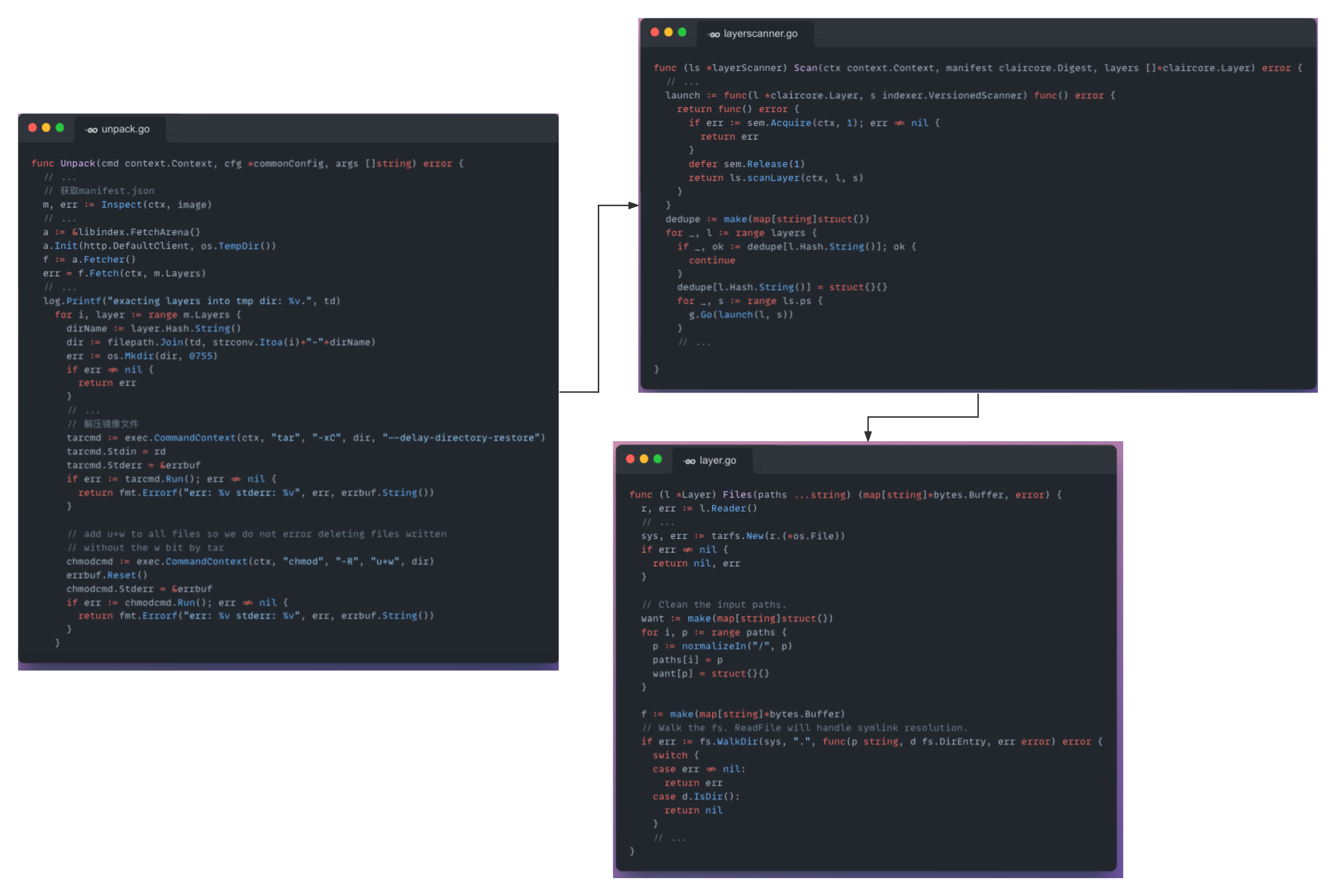
可以看到最开始由/cmd/cctool/unpack.go对tar文件的所有layer解压,之后通过./layer.go文件中Files函数对每一个解压的文件进行内容查找。即每一层对File传入想要查找的文件内容,之后将查找到的文件内容以map[string]*bytes.Buffer的形式返回,具体的代码如下
f := make(map[string]*bytes.Buffer)
// Walk the fs. ReadFile will handle symlink resolution.
if err := fs.WalkDir(sys, ".", func(p string, d fs.DirEntry, err error) error {
switch {
case err != nil:
return err
case d.IsDir():
return nil
}
if _, ok := want[p]; !ok {
return nil
}
delete(want, p)
b, err := fs.ReadFile(sys, p)
if err != nil {
return err
}
f[p] = bytes.NewBuffer(b)
return nil
}); err != nil {
return nil, err
}
// If there's nothing in the "f" map, we didn't find anything.
if len(f) == 0 {
return nil, ErrNotFound
}
return f, nil
可以看到,该方法有比较大的延迟性,查找一个文件需要每一个layer都扫描一遍,并且为了保证文件的有效性,即使当前layer存在指定文件,也需要继续完成所有layer文件的扫描。在新方法上面,主要增加了indexer文件夹,Layer的文件也从/indexer/controller/fetchlayers.go中的fetchLayers函数中获得,也从/indexer/controller/reduce.go的reduce函数扫描
// reduce determines which layers should be fetched/scanned and returns these layers
func reduce(ctx context.Context, store indexer.Store, scnrs indexer.VersionedScanners, layers []*claircore.Layer) ([]*claircore.Layer, error) {
do := []*claircore.Layer{}
for _, l := range layers {
for _, scnr := range scnrs {
ok, err := store.LayerScanned(ctx, l.Hash, scnr)
if err != nil {
zlog.Debug(ctx).
Stringer("layer", l.Hash).
Err(err).
Msg("unable to lookup layer")
return nil, err
}
if !ok {
do = append(do, l)
break
}
}
}
return do, nil
}
同时也将layer处理成仿真的文件系统,利用fs.WalkDir进行文件的分析,但是每一个组件都进行了完整的文件系统扫描,导致了多次冗余的遍历,下图为WalkDir的搜索结果
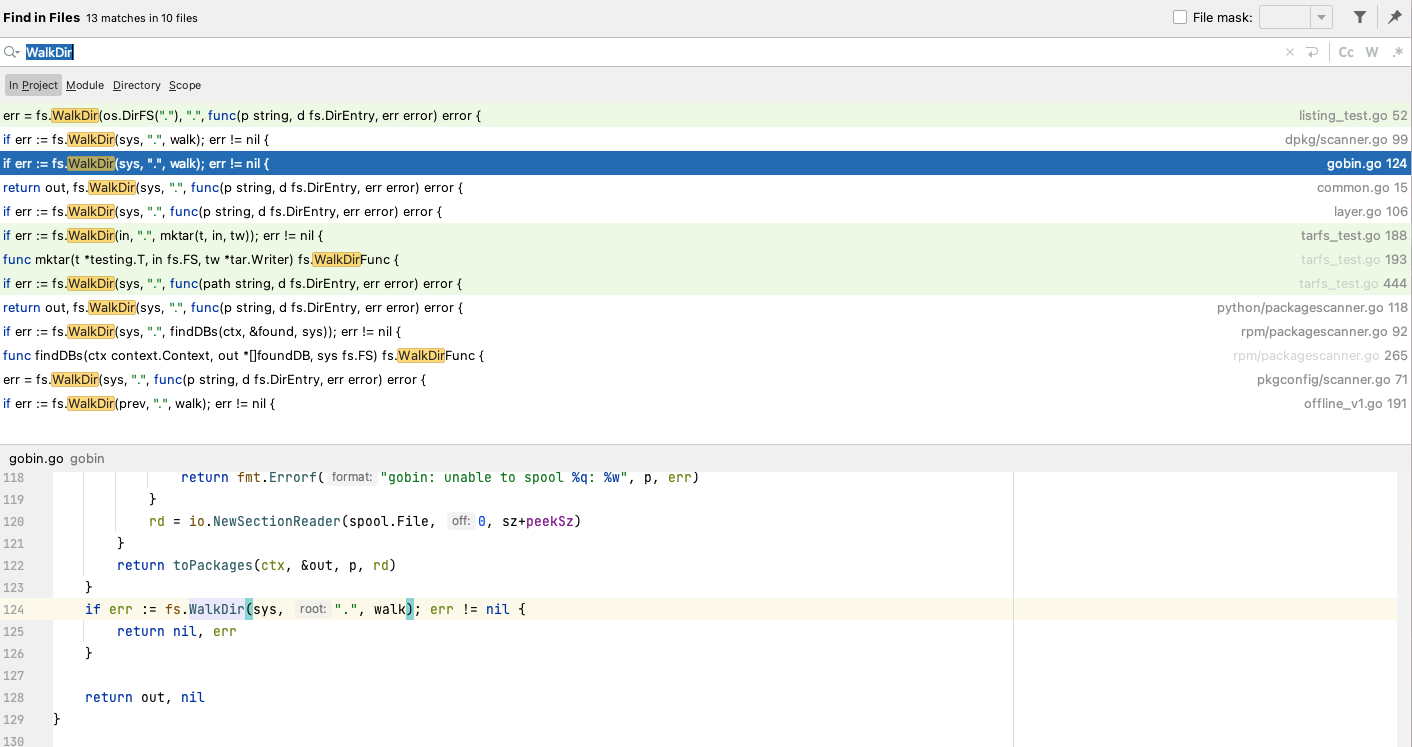
0X02 Trivy
trivy作为一个新兴容器扫描器,其易用性和高性能成为了容器扫描工具的一款精品,用镜像ID作为输入参数例子,trivy的分析流程如下
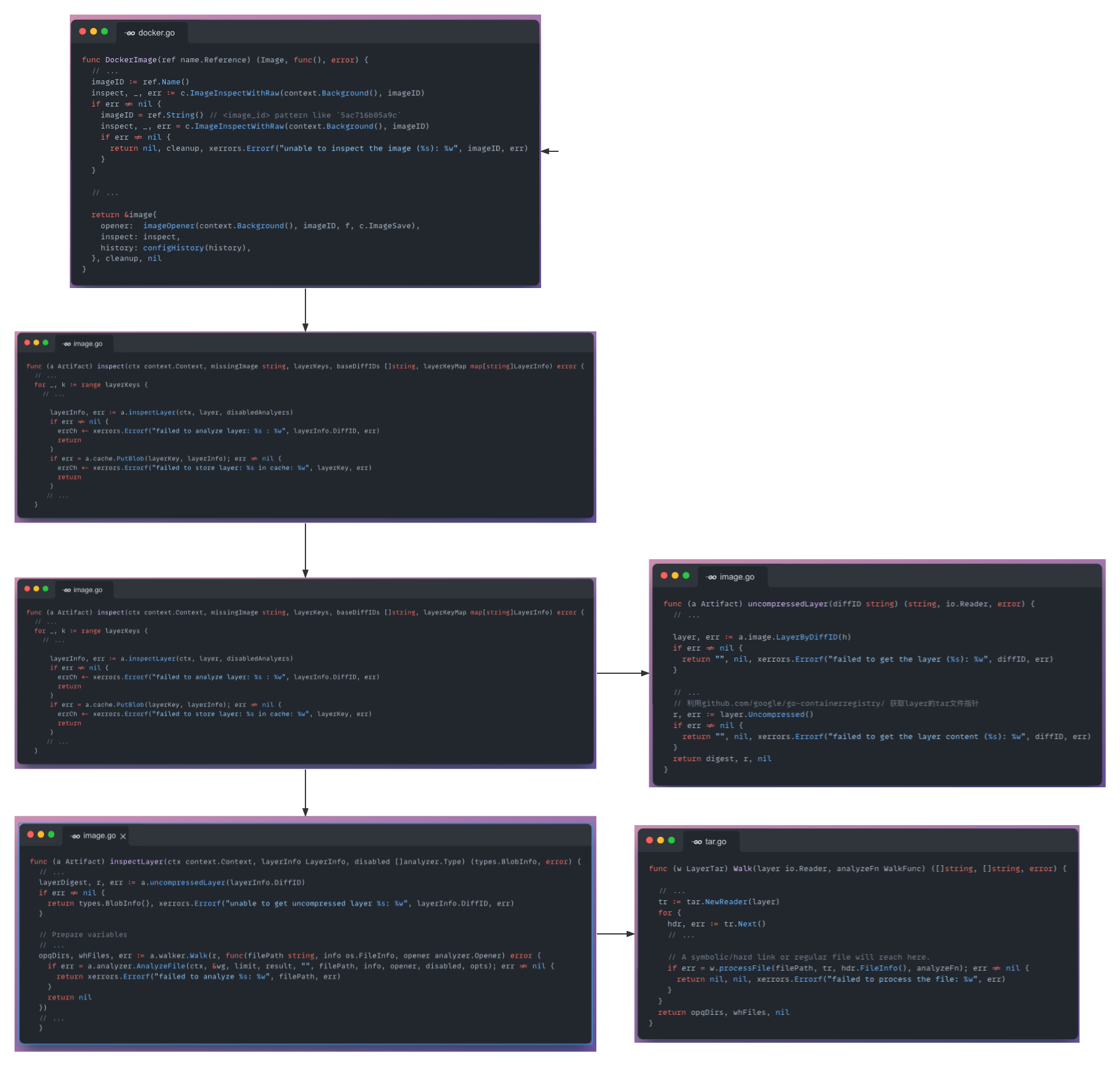
trivy使用了github.com/google/go-containerregistry/pkg/v1对layer进行提取,在Walk函数自定了函数对文件的类型进行分类。值得注意的是trivy对cache的使用次数非常多,每一个layer的分析以及单次镜像扫描使用了cache,在一个镜像扫描结束的时候tricy会将该次扫描的layer数据存入fanal的fanal.db中,可以从文件/pkg/fanal/applier/applier.go中的ApplyLayers函数看出。
func (a Applier) ApplyLayers(imageID string, layerKeys []string) (types.ArtifactDetail, error) {
var mergedKey string
// Try to restore the merged layer if the feature is enabled
if a.cacheMergedLayer {
var err error
mergedKey, err = calcMergedKey(layerKeys)
if err != nil {
return types.ArtifactDetail{}, xerrors.Errorf("failed to calculate a merged key: %w", err)
}
if b, err := a.cache.GetBlob(mergedKey); err == nil {
return b.ToArtifactDetail(), nil
}
}
var layers []types.BlobInfo
for _, key := range layerKeys {
// 查看每一个layer是否含有缓存
blob, _ := a.cache.GetBlob(key) // nolint
if blob.SchemaVersion == 0 {
return types.ArtifactDetail{}, xerrors.Errorf("layer cache missing: %s", key)
}
layers = append(layers, blob)
}
mergedLayer := ApplyLayers(layers)
if mergedLayer.OS == nil {
return mergedLayer, analyzer.ErrUnknownOS // send back package and apps info regardless
} else if mergedLayer.Packages == nil {
return mergedLayer, analyzer.ErrNoPkgsDetected // send back package and apps info regardless
}
// 查看镜像是否被缓存
imageInfo, _ := a.cache.GetArtifact(imageID) // nolint
mergedLayer.HistoryPackages = imageInfo.HistoryPackages
// Store the merged layer if the feature is enabled
if a.cacheMergedLayer {
if err := a.cache.PutBlob(mergedKey, mergedLayer.ToBlobInfo()); err != nil {
log.Logger.Error("Unable to cache the merged layer: %s", err)
}
}
return mergedLayer, nil
这使得trivy下一次再扫描相似的镜像或者对应镜像中包含相同layer的hash值的情况下速度会特别快。可以看到trivy在/pkg/commands/artifact/run.go中的scan函数跟进去之后对于layer的整理做了许多关于Blob的操作,这也是trivy在镜像扫描中速度占有极大优势的原因之一。
0X03 Vesta
在编写Vesta的过程中,其对镜像中的分层解析与以上两个成熟的扫描器基本相同,同样以镜像ID作为输入参数为例,vesta的解析流程如下
通过Docker cli拿到存储镜像的文件句柄 -> 将文件句柄解压到临时文件夹中 -> 将每一层的layer统一解压到制定的文件夹中 -> 分析供应链组建信息 -> 删除文件夹
在对每一个Layer解压的过程中忽略对文件大小超过1GB的文件的判断,从而避免因为容器为机器学习训练容器而导致的对超大训练文件的解压,但是此处依旧无法操作Docker Cli进行dump的过程中忽略这些文件,因此后续有待改进,vesta的文件layer解压非常简单
// Walk ignore the file which is vert large
func Walk(tarReader *tar.Reader, path string) error {
for hdr, err := tarReader.Next(); err != io.EOF; hdr, err = tarReader.Next() {
if err != nil {
return err
}
extractFile := filepath.Join(path, hdr.Name)
// ignore the file larger than 1GB
if hdr.Size > 1073741824 {
continue
}
switch hdr.Typeflag {
case tar.TypeDir:
if !exists(extractFile) {
if err := os.MkdirAll(extractFile, 0775); err != nil {
return err
}
}
case tar.TypeReg:
file, err := os.OpenFile(extractFile, os.O_CREATE|os.O_RDWR, os.FileMode(hdr.Mode))
if err != nil {
continue
}
_, err = io.Copy(file, tarReader)
if err != nil {
log.Printf("file %s can not extract: %v", hdr.Name, err)
}
default:
// ignore
}
}
return nil
}
为什么vesta的解压要落地成文件,而trivy, claircore不落地?
- vesta镜像分析增加了对container和image两个文件类型的适配,而一个运行的容器dump出来的tar文件就是一个完整的系统文件,并没有layer文件。同时后期考虑qcow2,img等文件格式的处理,此处统一输出成文件从而方便后续调用。
- 后期vesta也考虑增加文件内容合规检查,例如MySQL的密码配置文件,是否存在某些恶意文件等,短时间多次进行文件查找,因此转换成文件使用Linux文件树
- 目前还在对比缓存使用与内存占用量
此外,读者同时也能发现,三个layer整合方法都不约而同地利用了fs.WalkDir进行文件的查找,笔者认为,利用Linux的成熟的文件树查找算法要比单纯的进行tar压缩包文件查找效率要高很多,这也是vesta落地文件的原因之一。