0x01 分页
首先复习一下页的内容。
大小不等的固定分区和大小可变的分区技术在内存的使用上都是低效的,前者会产生内部碎片,后者会产生外部碎片。但假如内存被划分成大小固定相等的块,且块相对比较小,每个进程都有自己的页表,当它的所有页都装入到内存中时,页表被创建并被装入内存。同是操作系统需要为每个进程维护一个页表,页表给出了该进程的每一页对应的页框的位置。给出逻辑地址(页号、偏移量),处理器使用页表产生物理地址(页框号,偏移量)。其概念图如下
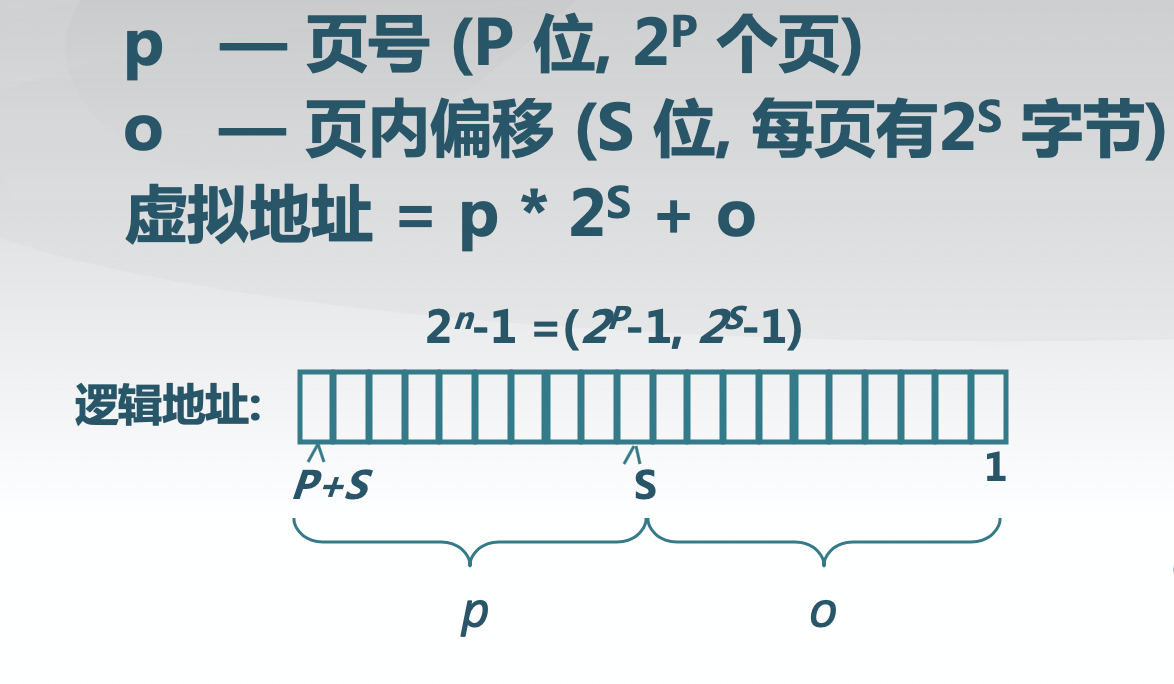
为了使分页方案更加方便,规定页的大小以及页框的大小必须是2的幂
页表项(Page Table Entry,简称PTE)包含有与内存中的页框相对应的页框号,通常每一个进程都有一个唯一的页表,页表项内存储着页表信息。原则上,每个虚拟访问可能引起两次物理内存访问:一次取相应的页表项,一次取需要的数据,因此,为了客服存储器访问时间加倍的问题,大多数虚拟内存为页表项使用一个特殊的高速缓存,通常称做转换检测缓冲区(Translation Lookaside Buffer, TLB)。如果在给定一个虚拟地址之后,如果在TLB没有找到需要的页表项并且页号检索进程也没有法相相应的页表项,则表示需要的页不在内存中,这时将产生一次存储器访问故障,称为缺页(page fault)中断。这时离开硬件作用范围,调用操作系统,由操作系统负责装入所需要的页,并更新页表。总结页表就是更有效地通过查询找到内存地址的一种方式。
ucore lab 3
通过ucore实验的lab3对page fault和页切换进行学习,其项目地址为https://objectkuan.gitbooks.io/ucore-docs/content/lab3/lab3_1_goals.html,首先进行第一个问题--给未被映射的地址映射上物理页,关于虚拟内存的详细分析可以阅读实验指导书。分页需要注意的是设置访问权限的时候需要参考页面所在 VMA 的权限,同时需要注意映射物理页时需要操作内存控制 结构所指定的页表,而不是内核的页表。实现虚存管理的关键是page fault异常处理,其过程主要涉及到函数__do_pafault的具体实现。比如,在程序的执行过程中由于某种原因(页框不存在/写只读页等)而使 CPU 无法最终访问到相应的物理内存单元,即无法完成从虚拟地址到物理地址映射时,CPU 会产生一次页访问异常,从而需要进行相应的页访问异常的中断服务例程。这个页访问异常处理的时机被操作系统充分利用来完成虚存管理,即实现“按需调页”/“页换入换出”处理的执行时机。当相关处理完成后,页访问异常服务例程会返回到产生异常的指令处重新执行,使得应用软件可以继续正常运行下去。
产生访问异常的原因主要有:
- 目标帧不存在(页表项全为0,即该线性地址与物理地址尚未建立映射或者已经撤销)
- 相应的物理页帧不在内存中(页表非空,但Present标志位=0,比如在swap分区或者磁盘文件上)
- 不满足访问权限(此时页表项P标志=1,但低权限的程序试图访问高权限的地址空间,或者有程序试图写只读页面)
直接看到函数do_pgfault
int
do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr) {
....
// try to find a pte, if pte's PT(Page Table) isn't existed, then create a PT.
// (notice the 3th parameter '1')
if ((ptep = get_pte(mm->pgdir, addr, 1)) == NULL) {
cprintf("get_pte in do_pgfault failed\n");
goto failed;
}
if (*ptep == 0) { // if the phy addr isn't exist, then alloc a page & map the phy addr with logical addr
if (pgdir_alloc_page(mm->pgdir, addr, perm) == NULL) {
cprintf("pgdir_alloc_page in do_pgfault failed\n");
goto failed;
}
}
else { // if this pte is a swap entry, then load data from disk to a page with phy addr
// and call page_insert to map the phy addr with logical addr
if(swap_init_ok) {
struct Page *page=NULL;
if ((ret = swap_in(mm, addr, &page)) != 0) {
cprintf("swap_in in do_pgfault failed\n");
goto failed;
}
page_insert(mm->pgdir, page, addr, perm);
swap_map_swappable(mm, addr, page, 1);
page->pra_vaddr = addr;
}
else {
cprintf("no swap_init_ok but ptep is %x, failed\n",*ptep);
goto failed;
}
}
ret = 0;
failed:
return ret;
}
主要注意到对ptep指针的判断,此处为初始化ptep参数,如果ptep参数为0,则表示物理页面的地址不存在,因此重新设置物理页的地址,继续跟进pgdir_alloc_page函数
struct Page *
pgdir_alloc_page(pde_t *pgdir, uintptr_t la, uint32_t perm) {
struct Page *page = alloc_page();
if (page != NULL) {
if (page_insert(pgdir, page, la, perm) != 0) {
free_page(page);
return NULL;
}
if (swap_init_ok){
swap_map_swappable(check_mm_struct, la, page, 0);
page->pra_vaddr=la;
assert(page_ref(page) == 1);
}
}
return page;
}
定义page的结构体并且分配页,通过alloc_page函数分页,其alloc_pag又通过pmm_manager的alloc_page来得到页,其方法来自于Page结构体中的alloc_pages算法。最终进行页分配的代码为Page的结构体指针函数default_alloc_pages
static struct Page *
default_alloc_pages(size_t n) {
assert(n > 0);
if (n > nr_free) {
return NULL;
}
struct Page *page = NULL;
list_entry_t *le = &free_list;
while ((le = list_next(le)) != &free_list) {
struct Page *p = le2page(le, page_link);
if (p->property >= n) {
page = p;
break;
}
}
if (page != NULL) {
if (page->property > n) {
struct Page *p = page + n;
p->property = page->property - n;
SetPageProperty(p);
list_add_after(&(page->page_link), &(p->page_link));
}
list_del(&(page->page_link));
nr_free -= n;
ClearPageProperty(page);
}
return page;
}
在C中使用链表来进行页表的使用。再回到do_pgfault函数中,如果ptep地址不为0,则从物理页表中加载数据,最后返回换页结果。执行make qemu得到换页的debug信息
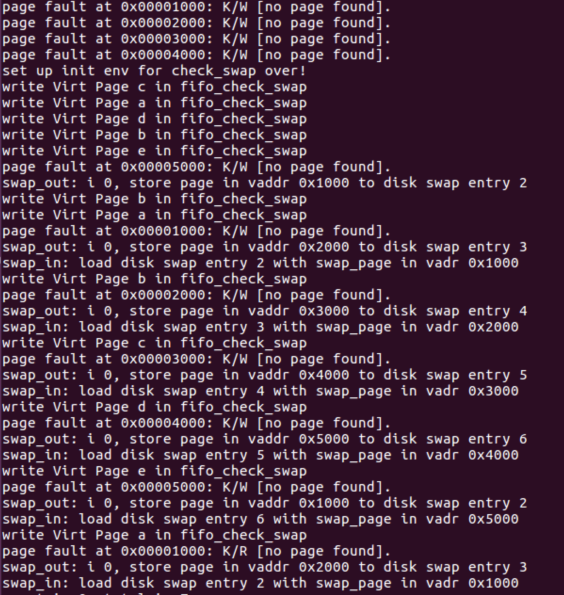
关于页面替换机制详情可以参考实验指导书https://objectkuan.gitbooks.io/ucore-docs/content/lab3/lab3_5_2_page_swapping_principles.html
0x02 Copy-On-Write
引用wiki上面的语句就是,写时复制技术是为了高效地实现一个在修改的资源上的“重复”或者“复制”操作,如果一个资源是重复但是没有被认证的时候,他是没有必要去创建一个新的资源,这个资源能够被分享在原始和复制中间。被修改的资源忍让必须创建一个拷贝,因此这个技术是:拷贝操作被推迟直到第一次写入的时候。通过这个方法分享这个资源,它可以显着减少未修改副本的资源消耗,同时为资源修改操作增加少量开销。
Copy on write 的主要用途是在fork指令实现的过程的时候共享操作系统进程的虚拟内存。通常地,进程不会去修改任何内存而且会马上执行一个新的进程,完全替换地址空间。因此,他可能会在一个fork拷贝所有进程内存的时候造成浪费,因此替换成copy-on-write机制。因此对于fork方法来说,COW机制的实验原理是:fork之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page fault),陷入kernel的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。
通过将某些内存页面标记为只读并保留对该页面的引用数,可以使用页面表有效地实现写时复制。 当将数据写入这些页面时,尽管allocation重新分配在只有一个引用的时候能够被跳过,但是内核将拦截写入尝试并分配一个新的物理页面,并使用写时复制数据进行初始化。 然后,内核使用新的(可写的)页面更新页面表,减少引用数,然后执行写操作。 新分配的资源可确保一个进程的内存更改在另一进程中不可见。
通过将物理内存页面填充为零页,可以扩展写时复制技术以支持有效的内存分配。 分配内存后,所有返回的页面均指向零页面,并且都标记为写时复制。 这样,在写入数据之前,不会为该进程分配物理内存,从而允许进程保留比物理内存更多的虚拟内存并稀疏使用内存,这有可能耗尽虚拟地址空间。 组合算法类似于需求分页。 当程序申请匿名内存页时,linux系统为了节省时间和空间并不会真的申请一块物理内存,而是将所有申请统一映射到一块预先申请好值为零的物理内存页,当程序发生写入操作时,才会真正申请内存页,这一块预先申请好值为零的页即为零页(zero page),且零页是只读的。
加载一个程序的依赖同样使用了读后写技术,动态链接器将库映射为私有库,对库的任何写操作都将触发虚拟内存管理中的COW。常用的函数是mmap。
通过Linux源码学习COW机制,本文使用的是Linux4.7
首先fork创建子进程的时候会和父进程共享资源,首先看到kernel/fork.c中的_do_fork函数
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
int trace = 0;
long nr;
....
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
....
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
其参数解析如下
clone_flag: 克隆标签
stack_start: 栈初始地址
stack_size: 栈大小
parent_tidptr: 父进程页表寄存器标识
child_tidptr: 子进程页表寄存器标识
在copy_process函数里面经过一系列判断之后进入到copy_mm函数,到达dup_mm,dup_mm描述为重新分配一个新的mm结构体,mm结构体即为内存描述符,其传入的参数task_struct 即为进程描述符,一些列跳转最终转入copy_one_pte,因此_do_fork函数分配过程如下
_do_fork -> copy_process -> copy_mm ->dup_mm -> dup_mmap -> copy_page_range -> copy_pud_range -> copy_pmd_range -> copy_pte_range -> copy_one_pte
copy_one_pte 传入参数解释如下
dst_mm: 目的内存描述符地址
src_mm: 来源内存描述符地址
dst_pte: 目的页表项
src_pte: 来源页表项
vma: 虚拟地址空间结构体
addr: 拷贝页表项的地址
rss: 为page的类型分配空间,一般NR_MM_COUNTERS 为3种
在is_cow_mapping处判断是否为cow机制,如果是则写入read-only标签,代码如下
/*
* If it's a COW mapping, write protect it both
* in the parent and the child
*/
if (is_cow_mapping(vm_flags)) {
ptep_set_wrprotect(src_mm, addr, src_pte);
pte = pte_wrprotect(pte);
}
static inline bool is_cow_mapping(vm_flags_t flags)
{
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE; // 判断内存是否可写
}
static inline pte_t pte_wrprotect(pte_t pte)
{
pte = clear_pte_bit(pte, __pgprot(PTE_WRITE)); //清可写位
pte = set_pte_bit(pte, __pgprot(PTE_RDONLY)); //置位只读位
return pte;
}
此时,fork通过COW机制拷贝页表项已经完成,当有一方尝试写入的时候,就会发生处理器异常,处理器会判断出是COW缺页异常,与其直接相关的函数便是do_page_fault函数。调用函数过程为
do_page_fault -> __do_page_fault -> handle_mm_fault -> __handle_mm_fault -> handle_pte_fault
分析handle_pte_fault函数
if (!pte_present(entry)) {
if (pte_none(entry)) {
// 判断页表项是否存在,如果不存在且虚拟内存不是匿名的,则启用do_fault函数
if (vma_is_anonymous(vma))
return do_anonymous_page(mm, vma, address,
pte, pmd, flags);
else
return do_fault(mm, vma, address, pte, pmd,
flags, entry);
}
return do_swap_page(mm, vma, address,
pte, pmd, flags, entry);
}
static int do_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags, pte_t orig_pte)
{
....
if (!(flags & FAULT_FLAG_WRITE)) // 无法写入页面,启用只读模式
return do_read_fault(mm, vma, address, pmd, pgoff, flags,
orig_pte);
if (!(vma->vm_flags & VM_SHARED)) // 内存可分配信号,确定cow机制
return do_cow_fault(mm, vma, address, pmd, pgoff, flags,
orig_pte);
return do_shared_fault(mm, vma, address, pmd, pgoff, flags, orig_pte);
}
static int do_cow_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
....
// 重新分配虚拟内存
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
...
// 进行中断机制
ret = __do_fault(vma, address, pgoff, flags, new_page, &fault_page,
&fault_entry);
...
// 设置新的页表项
do_set_pte(vma, address, new_page, pte, true, true);
// 将改变提交到cgroup中
mem_cgroup_commit_charge(new_page, memcg, false, false);
// 更新lru(最近最少使用)算法
lru_cache_add_active_or_unevictable(new_page, vma);
...
}
再看__do_fault函数
static int __do_fault(struct vm_area_struct *vma, unsigned long address,
pgoff_t pgoff, unsigned int flags,
struct page *cow_page, struct page **page,
void **entry)
{
...
ret = vma->vm_ops->fault(vma, &vmf);
...
return ret;
}
mm/mmap.c
static const struct vm_operations_struct special_mapping_vmops = {
.close = special_mapping_close,
.fault = special_mapping_fault, // 调入special_mapping_fault方法
.name = special_mapping_name,
};
static int special_mapping_fault(struct vm_area_struct *vma,
struct vm_fault *vmf)
{
...
if (*pages) {
struct page *page = *pages;
get_page(page); //增进page结构的引用计数
vmf->page = page;
return 0;
}
...
}
最后回到do_cow_fault中进行do_set_pte设置页表项操作。
void do_set_pte(struct vm_area_struct *vma, unsigned long address,
struct page *page, pte_t *pte, bool write, bool anon)
{
...
entry = mk_pte(page, vma->vm_page_prot);
//此处传入的write和anon都为true,因此entry被覆盖
if (write) //判断是否可写
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
if (anon) { // 判断是否是匿名页面
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, address, false);
} else {
inc_mm_counter_fast(vma->vm_mm, mm_counter_file(page));
page_add_file_rmap(page);
}
...
}
include/linux/mm.h
/*
* Do pte_mkwrite, but only if the vma says VM_WRITE. We do this when
* servicing faults for write access. In the normal case, do always want
* pte_mkwrite. But get_user_pages can cause write faults for mappings
* that do not have writing enabled, when used by access_process_vm.
*/
static inline pte_t maybe_mkwrite(pte_t pte, struct vm_area_struct *vma)
{
if (likely(vma->vm_flags & VM_WRITE))
pte = pte_mkwrite(pte); // 设置页表项符号
return pte;
}
static inline pte_t pte_mkwrite(pte_t pte)
{
return pte_set_flags(pte, _PAGE_RW); //设置页表读写符号
}
在maybe_mkwrite这里注释表明只有当虚拟内存被标识为可写的时候曹才会进行页表项的操作,否则直接返回pte,最后写入cgroup内存,更新lru缓存。回到handle_pte_fault函数,在经过is_cow_mapping之后,进入下列代码
if (flags & FAULT_FLAG_WRITE) {
//页表项存在,物理页存在内存,但是vma是可写,pte页表项是只读属性
if (!pte_write(entry))
return do_wp_page(mm, vma, address,
pte, pmd, ptl, entry);
entry = pte_mkdirty(entry);
}
static int do_wp_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
spinlock_t *ptl, pte_t orig_pte)
__releases(ptl)
{
...
if (PageAnon(old_page) && !PageKsm(old_page)) {
...
// 判断是否可以重新使用这个页
if (reuse_swap_page(old_page, &total_mapcount)) {
if (total_mapcount == 1) {
/*
* The page is all ours. Move it to
* our anon_vma so the rmap code will
* not search our parent or siblings.
* Protected against the rmap code by
* the page lock.
*/
page_move_anon_rmap(old_page, vma);
}
....
}
...
return wp_page_copy(mm, vma, address, page_table, pmd,
orig_pte, old_page);
}
之后便进入到了wp_page_copy,也就是cow主要代码里面
static int wp_page_copy(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
pte_t orig_pte, struct page *old_page)
{
....
if (likely(pte_same(*page_table, orig_pte))) {
...
// 通过vma的访问权限和新页的页描述符来构建页表项的值
entry = mk_pte(new_page, vma->vm_page_prot);
// 设置该页表项属性为可写,并且设置页表为脏
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
// 将页表项原有的值清除,然后刷新地址发生缺页地址对应的tlb
ptep_clear_flush_notify(vma, address, page_table);
// 将新页放入到vma对应的匿名页中
page_add_new_anon_rmap(new_page, vma, address, false);
mem_cgroup_commit_charge(new_page, memcg, false, false);
lru_cache_add_active_or_unevictable(new_page, vma);
set_pte_at_notify(mm, address, page_table, entry);
update_mmu_cache(vma, address, page_table);
...
}
这里的脏页的解释为——因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
总结一下COW机制:当fork发生时,子进程会和父进程共享内存,并将双方进程中对应的页表项修改为read-only,当有一方试图写共享的页时,会触发COW缺页异常,缺页异常处理程序会为写操作的一方分配新的物理页,并将原来共享的物理页内容拷贝到新页,然后建立新页的页表映射关系,这样写操作的进程就可以继续执行,不会影响另一方,当共享的页面最终只有一个拥有者(即使其他映射页面到自己页表的进程都发生写时复制分配了新的物理页),这个时候如果拥有者进程想要写这个页就会重新使用这个页而不用分配新页。
0x03 Dirty COW
Dirty cow漏洞,编号CVE-2016-5195,其原理为在COW机制下通过条件竞争来损坏内存映射的只读条件,能够使得攻击者绕过文件的只读权限从而写入文件。首先查看git的修复记录
commit 4ceb5db9757aaeadcf8fbbf97d76bd42aa4df0d6
Author: Linus Torvalds <torvalds@g5.osdl.org>
Date: Mon Aug 1 11:14:49 2005 -0700Fix get_user_pages() race for write access
There's no real guarantee that handle_mm_fault() will always be able to
break a COW situation - if an update from another thread ends up
modifying the page table some way, handle_mm_fault() may end up
requiring us to re-try the operation.
That's normally fine, but get_user_pages() ended up re-trying it as a
read, and thus a write access could in theory end up losing the dirty
bit or be done on a page that had not been properly COW'ed.
This makes get_user_pages() always retry write accesses as write
accesses by making "follow_page()" require that a writable follow has
the dirty bit set. That simplifies the code and solves the race: if the
COW break fails for some reason, we'll just loop around and try again.
修改记录主要新增加了FOLL_COW标示对竞争标志做一个双重认证。从修复记录标记中可以看到问题出现在get_user_pages函数中,从而对handle_mm_fault之后方法的页表项进行利用,源码大致分析已经分析出来,从https://github.com/dirtycow/dirtycow.github.io/wiki/VulnerabilityDetails看到漏洞的产生过程。
faultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
do_fault <- pte is not present
do_cow_fault <- FAULT_FLAG_WRITE
alloc_set_pte
maybe_mkwrite(pte_mkdirty(entry), vma) <- mark the page dirty
but keep it RO
# Returns with 0 and retry
follow_page_mask
follow_page_pte
(flags & FOLL_WRITE) && !pte_write(pte) <- retry faultfaultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
FAULT_FLAG_WRITE && !pte_write
do_wp_page
PageAnon() <- this is CoWed page already
reuse_swap_page <- page is exclusively ours
wp_page_reuse
maybe_mkwrite <- dirty but RO again
ret = VM_FAULT_WRITE
((ret & VM_FAULT_WRITE) && !(vma->vm_flags & VM_WRITE)) <- we drop FOLL_WRITE# Returns with 0 and retry as a read fault
cond_resched -> different thread will now unmap via madvise
follow_page_mask
!pte_present && pte_none
faultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
do_fault <- pte is not present
do_read_fault <- this is a read fault and we will get pagecache
page!
路线为__get_user_pages -> follow_page_mask -> faultin_page -> handle_mm_fault -> __handle_mm_fault -> handle_pte_fault 最终设置脏页,分配不带_PAGE_RW标记的匿名内存页,返回值为0。分析一下基于fork的exp pokemon.c,位于https://github.com/dirtycow/dirtycow.github.io/blob/master/pokemon.c,利用PSTRACE来利用COW,过程为首先打开一个只读文件,记录文件描述符fd,通过mmap映射文件内存区,fork一个新的进程,如果新的进程不为主进程则等待该进程,尝试1万次通过跟踪进程进行进行文件的内容写入。如果进程pid为主进程,即pid=0,则创建madviseThread线程,该线程通过循环2*10的8次方来进行cow竞争,对子进程进行跟踪,再给子进程发送信号,等待线程结束,完成利用。而另一个exp dirtyc0w.c https://github.com/dirtycow/dirtycow.github.io/blob/master/dirtyc0w.c则是利用/proc/self/mem文件通过mmap分配的内存来竞争写入只读文件的区域。
从follow_page_mask函数开始看起
第一次查找页表
struct page *follow_page_mask(struct vm_area_struct *vma,
unsigned long address, unsigned int flags,
unsigned int *page_mask)
{
...
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
return no_page_table(vma, flags);
pud = pud_offset(pgd, address);
if (pud_none(*pud))
return no_page_table(vma, flags);
if (pud_huge(*pud) && vma->vm_flags & VM_HUGETLB) {
page = follow_huge_pud(mm, address, pud, flags);
if (page)
return page;
return no_page_table(vma, flags);
}
if (unlikely(pud_bad(*pud)))
return no_page_table(vma, flags);
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
return no_page_table(vma, flags);
if (pmd_huge(*pmd) && vma->vm_flags & VM_HUGETLB) {
page = follow_huge_pmd(mm, address, pmd, flags);
if (page)
return page;
return no_page_table(vma, flags);
}
if ((flags & FOLL_NUMA) && pmd_protnone(*pmd))
return no_page_table(vma, flags);
if (pmd_devmap(*pmd)) {
ptl = pmd_lock(mm, pmd);
page = follow_devmap_pmd(vma, address, pmd, flags);
spin_unlock(ptl);
if (page)
return page;
}
...
}
static struct page *no_page_table(struct vm_area_struct *vma,
unsigned int flags)
{
if ((flags & FOLL_DUMP) && (!vma->vm_ops || !vma->vm_ops->fault))
return ERR_PTR(-EFAULT);
return NULL;
}
在第一次查找时页还不在内存中之后,设置FAULT_FLAG_WRITE标记,之后进行handle_mm_fault等一些列跳转,设置页表项,此时页表还没有写入权限。看到faultin_page里
static int faultin_page(struct task_struct *tsk, struct vm_area_struct *vma,
unsigned long address, unsigned int *flags, int *nonblocking)
{
...
// 检查写权限
if (*flags & FOLL_WRITE)
fault_flags |= FAULT_FLAG_WRITE;
if (*flags & FOLL_REMOTE)
fault_flags |= FAULT_FLAG_REMOTE;
if (nonblocking)
fault_flags |= FAULT_FLAG_ALLOW_RETRY;
if (*flags & FOLL_NOWAIT)
fault_flags |= FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_RETRY_NOWAIT;
if (*flags & FOLL_TRIED) {
VM_WARN_ON_ONCE(fault_flags & FAULT_FLAG_ALLOW_RETRY);
fault_flags |= FAULT_FLAG_TRIED;
}
// 获取页表
ret = handle_mm_fault(mm, vma, address, fault_flags);
...
return 0;
}
此时第一次查询和page fault的处理结束,已经在内存中分配好了,该页是只读的匿名页。
第二次查找页表
此时FOLL_WRITE,同时因为page是只读的,后进入do_wp_page,do_wp_page会先判断是否真的需要复制当前页,因为第一次分配的页是一个匿名页且只有当前线程在使用,所以不用复制,直接使用,同时去掉查找标志FOLL_WRITE,至此第二次查找完成。
第三次查找页表
因为在第二次查找中FOLL_WRITE被去除,因此follow_page_mask会分配之前的页,完成COW机制。
因此竞争条件引发的流程如下:
- 调用follow_page_mask获取可写(FOLL_WRITE)内存页,发生缺页中断,调用faultin_page从磁盘中调入内存页。
- 通过goto entry再次调用follow_page_mask,请求可写(FOLL_WRITE)内存页,由于内存页没有可写权限,调用fault_page复制只读内存页并去掉FOLL_WRITE标志。
- 因为goto entry再次调用follow_page_mask会因为cond_resched主动弃权,引起系统调度其他程序,另一个程序使用madvise(MADV_DONTNEED)换出内存页。
- 程序再次被调度执行,调用follow_page_mask请求获取可写(FOLL_WRITE)内存页,发生缺页中断,再调用faultin_page从磁盘中调入内存页。
- 通过goto entry再次调用follow_page_mask,请求获取虚拟地址对应内存页(无FOLL_WRITE)并且返回page。
- 续进行写入操作,当内存数据同步到磁盘时,只读文件被改写。
Dirty Cow漏洞产生机制学习到这结束,同时该漏洞最常用来写入/etc/passwd中的拥有root权限的账号,一致可以使用root权限的账号进行操作,即可以在/etc/passwd文件中写入test:zSZ7Whrr8hgwY:0:0::/root/:/bin/bash 既可以拿到账号为test,密码为123456的root权限的账号
docker逃逸
Dirty Cow同样可以用来进行docker逃逸,其原理是对vDSO (virtual dvnamic shared object)小型共享库写入共享库,使得宿主机和容器公用这个共享库,造成docker逃逸。
vDSO介绍:vdso表述为虚拟ELF动态描述对象,是一种小的共享库,使得内核可以自动管理分配地址空间给所有的用户空间的应用。vDSO最常被C的库调用,以至于应用程序通常不需要关心他们自己。用 gettimeofday来举例子,该命令用户空间应用程序直接调用此系统调用,C库也间接调用此系统调用。考虑到timestamps或者timing循环或者轮询所有的话他们需要频繁地去了解目前正确的时间,应用程序在这个消息的私密模块中,即root用户或者其他任何没有权限的用户同样也不是在任何时候都是安全的,但是他们将会拿到同样的回答。因此,内核将需要回答这些消息的信息安排在了他们都能接触到的进程的内存中去,这样当调用gettimeofday的时候就会变成一个正常的函数并且只会占用很少的内存空间。同样,占用公共内存空间也会造成安全隐患。
Dirty Cow则利用了一个可以映射到所有进程并包含了经常被调用的函数的共享内存块,通过越权将payload写到vDSO中的一些闲置内存中,并改变函数的执行顺序,使得在执行正常函数之前调用这个shellcode。来看看POC https://github.com/scumjr/dirtycow-vdso/blob/master/0xdeadbeef.c,该POC原理为当一个程序调用clock_gettime()的时候执行,如果进程为root权限并且/tmp/.X不存在,那么他会fork一个子进程,并且创建/tmp/.X文件,最终创建一个TCP反向连接的exploit。
写入vDSO可以学习https://github.com/scumjr/the-sea-watcher/blob/master/hijack_vdso.c
0xFF Reference
- 操作系统精髓与设计原理(第6版)
- https://objectkuan.gitbooks.io/ucore-docs/content/lab3/lab3_5_2_page_swapping_principles.html
- https://github.com/dirtycow/dirtycow.github.io/wiki/VulnerabilityDetails
- https://en.wikipedia.org/wiki/Copy-on-write
- https://juejin.cn/post/6844903702373859335
- https://blog.csdn.net/qq_26768741/article/details/54375524
- https://cloud.tencent.com/developer/article/1690373
- https://stackoverflow.com/questions/60363929/how-does-fork-process-mark-parents-ptes-as-read-only
- https://www.anquanke.com/post/id/89096#h3-9
- https://man7.org/linux/man-pages/man7/vdso.7.html